https://blog.daum.net/rightvoice/1673
[내용정리] oData
oData확인방법. https://www.odata.org/getting-started/basic-tutorial <== oData의 query [옵션]을 대한 내용들 https://pragmatiqa.com/xodata/odatadir.html <== oData를 Visual하게 확인한다. https://www.y..
blog.daum.net
oData확인방법.
https://www.odata.org/getting-started/basic-tutorial <== oData의 query [옵션]을 대한 내용들
https://pragmatiqa.com/xodata/odatadir.html <== oData를 Visual하게 확인한다.
https://www.youtube.com/playlist?list=PLQHTTlL0gF_d86LX5xbGj4jqUAIT7nsPr
https://www.youtube.com/watch?v=nblHq4yThV8&list=PLILIWf5Xau49tWwS-GIIX40yyT-ws6dXd&index=2&t=0s
stackoverflow.com/questions/38089753/odata-v4-what-are-functions-and-actions-in-simple-terms
www.youtube.com/watch?v=9jjmfB0wIGQ
oData의 Action : DB에 상태를 변경하지 않으므로 side effect가 없는 fuction을 말한다.
oData의 function : DB에 상태를 변경하므로 side effect가 있을 수 있는 function을 말한다.
본인이 Web개발 전문가가 아니고, 해당 분양에서 일을 전문적으로 하지 않은상태에서
공부를 통한 내용을 정리하다 보니, 항시 잘못된 정보가 전달될 수 있으므로 Cross Checking이 필요하다.
이런 부담감을 줄이기 위해. 이 블러그의 제목에 "나만의 글쓰기"라고 들어있는 것임에 유념하기 바란다.
개인적으로 공부함에 있어 왜?(Why)가 가장 중요하다고 생각하고 있다.
왜 라는 질문에 답할 수 있으면, 납득할 수 있고, 납득할수 있으면 동기가 부여되기 때문이다.
UI5를 공부하는데 oData를 왜 알아야 할까?
이렇게 상상해보자.
SAP사가 WebApp을 만들기위해 UI5라는 Framework을 만들었다.
그런데 DB Server와 Web Browser간에 Data를 송수신을 어떻게 해야할까 고민하고 있었는데, oData라는 MS에서 제안한 방식이 보였다.
이 방식을 사용하면 무료인데다, UI5 framework에 잘 어울리겠다고 판단했다.
이제 통신 방식이 결정되었으므로, 해당 방식에 맞게 화면단을 구성해야 한다.
oData에 어울리는 화면단 UI5의 DataBinding을 개발했다. DataBiding의 용어도 oData가 제안하는 방식에 따랐고 구조도 따랐다.
oData에 어울리는 서버단 ABAP의 Gateway를 개발했다. oData에 제안한 metadata의 생성방법을 따랐고, 용어도 맞게 따랐다.
자 이제 우리가 DataBinding을 알기위해 Server단 Gateway를 알기위해 우선적으로 알아야 하는 것이 oData라는 사실에 동감할 수 있겠는가? 이제 납득이 되었으므로 아래의 내용을 살펴 보자.
( 아래의 내용이 이해가 한번에 안될 수도 있다, 향후 DataBinding, Gateway를 통한 oData생성시 다시 와서 읽어본다면 도움이 될것이다. )
oData는 REST API의 대표주자이다.
oData는 REST의 영감을 받아 RESTFUL architecture착안된 Data전송용 Protocol이다.
따라서 REST를 이해하는 것이 oData를 이해하는 시작점이다.
payload : 운송관점에 돈(pay)을 지불해야 하는 적재(load)만이 관심사항이다. 운송수단,운송자는 관심사항이 아니다. 이와 마찬가지로 web통신시 header, meta정보는 관심사항이 아니다. 오직 request에 의한 Body와 그에대한 응답결과인 response의 body만이 관심사항이다.
oData의 Response가 JSON형태로 전달되는데 이를 보다 쉽게 읽기위하여 Chrome사용자라면
JSONView를 설치하도록 하자. ( 구글 검색어 : json extension for chrome )
REST(REpresentational State Transfer)란 무엇일까?
REST를 이해하기 위해 이전의 SOAP라는 것을 먼저 간단히 알고 넘어갈 필요가 있다. (왜? SOAP의 단점을 개선하기 위해 나온것이므로)
SOAP( Simple Object Access Protocol ) : 이종 시스템간 통신을 수행하기 위한 Web Service라는 기술을 적용하는 Protocol이다. 기존 internet 통신 protocol( http, https, smtp )위에 상위 protocol을 만들어서 서로간에 통신약속을 정해 데이타를 주고 받는다. 이 때 사용되는 언어가 WSDL( Web Service Description Lanaguae )이며 주로 XML 문법을 사용한다. protocol위에 protocol을 놓은것이라 데이타양도 많고 느리다. 결정적으로 UUDI( Universal Description Discovery and Intergration )라는 Service Broker를 거치지 않으면 동작을 하지 않는 구조가 문제가 되었다. SOAP를 사용하는 방식을 Service추구 방식[ SOA( Service Oriented Architecture ) ]이라 한다.

Web services repository를 없애자는 것이 REST개념의 시작점이다.
SOAP의 단점 그중 UUDI을 제거하기 위한 방식으로 탄생한 방법이 REST이다. 그리고 기존의 Service추구(SOA)방식에서 자원[ ROA( Resource Oriented Architecture ) ]추구 방식으로 전환하게 된다.
REST는 developement paradigm이지 HTTP나 SOAP와 같은 Protocol이 아니다. 서로간에 정한 큰 약속 규범같은 것이다.
간단하고 가벼운 mechanism을 가지고 서로간에 통신할 수 있는 구조를 가지고 있다.
Resource를 다루는 방식은 전통적인[ SOAP(각 요청마다 요청에 맞는 응답을 만드는 방식)/RFC ]과는 달리 identifier에 따른 응답을 기초로 하고 있다.
=> SOAP : getEmployee , getCustomer [Action] ( RFC처럼 기능단위로 )
=> REST : Employee, Customer [Noun] ( Table처럼 자체가 Resource임 )
RESTful을 만족시키는 통신을 위해 아래의 6가지를 지켜야 한다.
=> REST라는 개념으로 Service를 제공하는 API인가요? 예 그럼 이 Service는 RESTful 하군요.
1) Client-Server : Client는 Request만들어서 Server에 전송하고, Server는 Respond를 만들어서 전송해 준다.
2) Stateless : 아래 설명참고. 이러한 방식은 Client와 Server가 누구인지에 상관없이 decoupling되어 개발할 수 있는 여지를 제공해 준다.
3) Cacheable : Client에서 Request를 통해 Response를 받았는데 동일한 내용의 요청한 경우 Client에 존재하는 이미 Cache에 저장된 내역을 가지고 작업을 수행한다.
4) Uniform Interface : architecture에 따른 정해진 방식으로 대화를 해야한다. 모든 개발자는 이 규칙에 따른다.
5) Layered System : 아래의 SAP Layered System을 참고할것.
6) Code on Demand(optional) : 모든 데이타를 한번에 보내는 것이 아니라, 필요에 따라 그때 그때 관련 데이타만 보내어 performance를 개선한다.
REST는 Stateless 방식을 사용한다.
1) Server로 접수된 모든 Request는 oData로 가공된 Respond가 발생되어 전달되면 request의 정보는 없어진다.
2) client에 대한 session정보는 보관되지 않는다.
3) Request접수시 앞서실행된 Request에 대한 정보를 기억하거나 재호출 하지 않는다.
Stateful : SAPGUI처럼 Session을 계속유지하면서, 서버에 모든 기록을 남기면서 작업을 수행하는 방식, Internet Banking에 접속하면 접속유지 시간이 뜨면서, 이체시 앞선 화면을 만족하고 다음 화면을 진행하는 계속된 상태를 유지하는 방식. ( Client는 가벼우나, Server는 session을 유지하며 session정보를 계속해서 기록해야 하는 방식임)
Stateless : 검색엔진에서 검색시, 해당 요청이 1나 들어오면 1나 응답해주는 방식으로, 나는 현재 니가 누구인지 관심은 없고 너의 응답에만 대답해 주고 나는완료하겟다. ( Client는 요청시(Request) 응답(Response)를 정확히 받기 위해 관련된 모든 정보를 Request에 함께 보내주어야 한다. Client는 좀 무거우나, Server는 가벼워지는 방식 )
지금처럼 블러그에 글을 작성하면 Server는 해당 글에 고유번호를 할당하여 client에 전달해 놓고 신경을 쓰지 않는다. 만약 interent이 끊어진 상태에서 글을 작성하였다 하더라도, Posting할때 인터넷만 연결되어 잇다면 고유번호를 통해 글은 정상적으로 게시가 되게 된다.
REST COMMAND(API)로 [Create (POST) , Read(GET) , Update(PUT), 삭제(DELETE) ]를 사용한다.
1) GET [ READ ] : 1개의 entry를 얻거나 entry collection( table형태 )을 얻는다.
200(OK) , 404( Not Found )
2) POST [ CREATE ] : New entry를 생성한다.
201(Created), 404(Not Found), 409( Conflict)
3) PUT [ UPDATE ] : 존재하던 entry를 update한다.
200(OK), 204(No Content), 404(Not Found)
4) DELETE[ DELETE ] : entry를 제거한다.
200(OK), 404(Not Found)
5) PATCH : 존재하던 entry의 단일 속성( column, field )를 update한다.
전통적인 방식(SOAP)은 Server측에서 Function(API)을 만들어 원하는 데이타를 가져오거나 갱신하는 전용 API를 개발하는 방식이나, oData를 이용하면 URI명령(마치 DB측 SQL명령을 내리듯)을 통해 서버측 데이타를 CRUD하는 것을 수행할 수 있다.
이는 마치 Web을 위한 ODBC( Online Database Connectivity )처럼 보인다.
oData를 통한 SAP통신
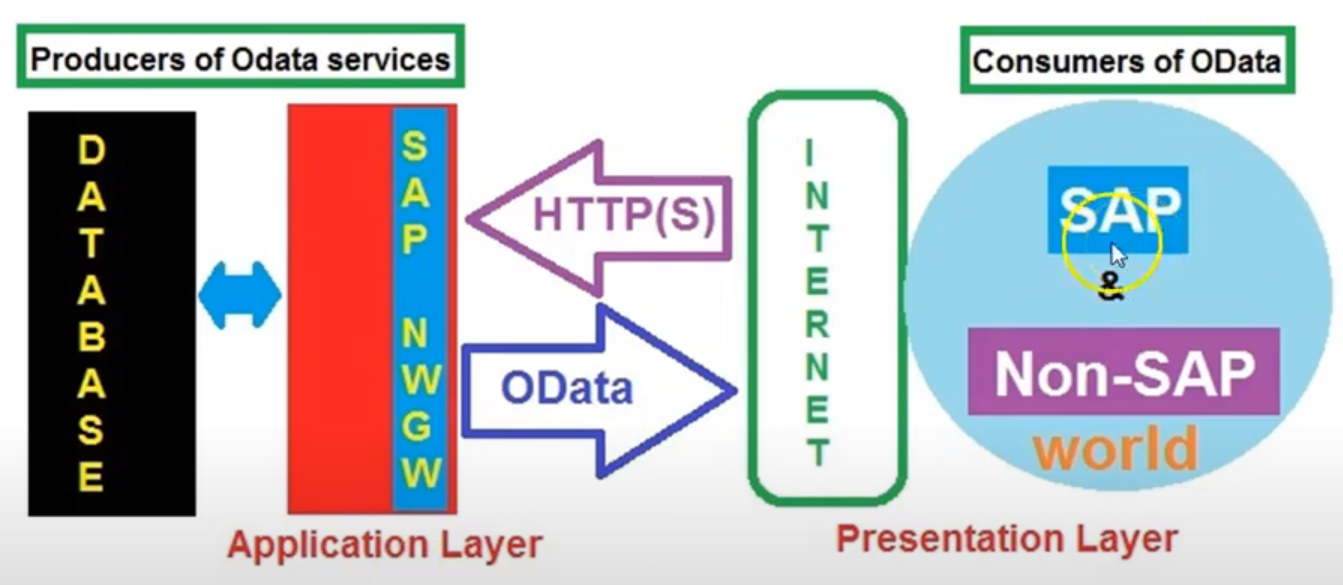
Application Layer ( Application Server )
Presentation Layer : Fiori, SAPUI5, OPENUI5, Web-Program 아무거나 표현되는 영역
1) Presentation Layer은 App( made by ui5 )이 HTTP를 통해 Request( 사원정보를 알려주세요 )를 보낸다.
2) Application Layer는 외부 대화상자( SAP NWGW / SAP Netweaver Gateway )를 통해 Request를 접수한다.
3) SAP Netweaver Gateway는 해당 요청에 따른 데이타를 확보한다.
4) SAP Netweaver Gateway는 해당 정보의 DataSet을 oData로 변환하여 HTTP를 통해 Respond로 전달한다.
5) Presentation Layer는 Request에 대한 Respond를 접수하여 화면에서 처리해 준다.
SAP Layered System.

SAP Gateway 배치방법.
1) Central Hub Deployment of SAP Gateway
아랫쪽 파란상자는 CRM, HR, SRM, SCM, BW 등의 Business System이 된다. UI5등의 App은 Business System안에서 개발되고, 사용을 위한 윗쪽 파란상자( Gateway Server System )에 등록되어 사용되어 진다. oData는 아랫쪽 상자의 [SAP Gateway IW_BEP]에서 개발되어진다. 개발된 UI5에서 Request가 발생하면 윗쪽상자(Gateway Server System)이 접수하고, 해당 oData에 MDC&DPC가 호출되어 Bussiness System에게 데이타를 요청하게 된다. 만약 oData의 개발을 윗쪽상자에게 위임해 버리면 아랫쪽상자에게 RFC로 데이타를 요청해야 하므로 추가 공수가 발생할 수 있다.
윗쪽파란상자를 우리는 FrontEnd Server라 부른다.
아랫파란상자를 우리는 BackEnd Server라 부른다.
2) Embedded Deployment of SAP Gateway
상자가 1개로 구성되어 있다. hardware적으로 Back-end와 Front-end가 하나의 Server에서 모든 것을 처리한다. 그러나 Software적으로는 Central Hub와 동일하다.

같은 Central hub라 해도 oData의 생성을 Front또는 Back에서 수행할 수 있다. 1안이 추천방법이다.

SAP_GWFND( Component )가 SAP Netweaver Gateway System이며 Frontend/Backend Server둘다에 설치되어 있어야 한다.
oData의 사용은 어떠한 장점을 주는가?
1) XML/ JSON은 이미 시장에서 많이 사용하고 검증된 이종간 시스템에서 사용하는 text전송방식이다.
XML대비 JSON은 같은데이타임에도 약 40%의 전송데이타 절약이 발생하여 Moblie App개발시 보다 선호된다.
2) 화면쪽(Front-end) 개발자는 ABAP / SAP를 알지못해도 oData라는 공개된 방식을 이해하고 있으면 개발하는데 지장없다.
(그러나, 국내시장에서는 oData를 통해 개발된 프로그램이 많지 않고, Spring framework등의 선점하고 있어 해당 방식을 따른다. )
3) 화면쪽(Front-end)과 데이타쪽(Back-end)개발자는 독립적으로 일할수 있으며, 같은팀이 아니어도 개발을 완료할 수 있다.
(그러나, 발주사 입장에서는 기존 방식으로 (ABAP개발)만 사용하면 화면을 개발할 수 있는데, Fornt-End의 개발로 인해 개발 시간 2배, 개발비용 2배라는 딜레마에 빠지게 한다. )
oData의 필요성

oData는 최초 2007년 MicroSoft에 의해서 개발되어(현재는 MS는 손을 놓아버림) 2010년 무료로 Open하였다. 현재 oasis에 의해 Open Source형태로 관리되고 있다.
SAP사는 2009년 SAP NetWeaver Gateway에 투자를 시작하여 2011년에 SAP NetWeaver Gateway(oData Service를 제공해 주는tool) 를 제공하기 시작 하였다.
국내자료가 거의 없는 것으로 보아, 국내에서는 잘 사용하지 않는것 같으나 , Amazon / Apple 등이 사용하고 있고, 실질적으로 가장 많이 사용하는 곳은 SAP인듯 하다.
oData는 각종 기기( Smartphone, teblet, PC, Edge, Chorme, Cloud, MS-Office,etc.. )에 SAP에 Data를 요청할 때마다 그에 따른 RFC(SOAP)등을 개발하게 만들어 난개발되고 시간과 비용을 많이 발생시키게 되었다. 그러나 oData등의 표준화되고 공개된 방식을 채택함으로써 모든 SAP제품군에 대해서 동일한 방식으로 적용하고 사용 client는 해당 odata에 parameter를 변경함으로써 시간과 비용을 적약할 수 있다.

manifest.json 을 통해 URL을 확인한다.
1) web-Browser를 통해 접속을 시도한다.
=> https://services.odata.org/TripPinRESTierService/(S(id))/

oData임이 확인되었다.
2) $meta 데이타를 확인한다.
=> https://services.odata.org/TripPinRESTierService/(S(id))/$metadata

검색어로 [EntitySet]를 검색해서 나온 이름이 Table이 된다.
2-1) metadata 내용을 해석해 보자
=> oData의 metadata의 해석및 이해는 ABAP Server의 Gateway생성에 도움이 된다.
ABAP Server에서 Gateway를 통한 oData를 만든다는 것은 metadata를 만드는 행위이기 때문이다.
oData 버젼확인.
stackoverflow.com/questions/32501035/how-to-find-odata-version-from-metadata
- Check if <edmx:Edmx /> version is 4.0 (you know OData v4)
- Else, check if <edmx:DataServices /> has a MaxDataServiceVersion property (you now have highest available OData version)
- Else, check if <edmx:DataServices /> has a MinDataServiceVersion property (you now have minimum supported OData version)
- Else, check if <edmx:DataServices /> has a DataServiceVersion property (you now have minimum supported OData version)
V4가 아닌 OData 클라이언트는 response의 버젼 호환성을 위해 DataServiceVersion의 범위를 지정.
MinDataServiceVersion 및 MaxDataServiceVersion 헤더를 사용해야합니다 (SHOULD).
V2가 DataServiceVersion = "1.0" 으로 간주된다.

oData V4

oData V2
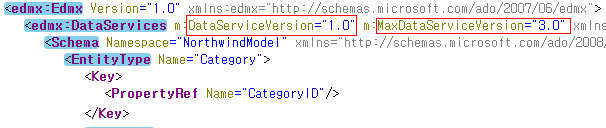
oData V3
Tag 설명

EDMX : Entity Data Model XML file을 말한다.
Schema NameSpace = "EPM_REF_SRV" : SAP의 Backend System에서 서비스하는 oData인 경우 [ External Service Name ]이 들어온다.
=> 이 이름을 기준으로 모든 Object의 상대적 위치가 결정된다.


EntityContainer : 1개의 oData를 설정함에 있어 제공되는 최외곽 Container이다.
EntityType : Table구조의 기본 Column Layout이다. ( Key Field와 Field의 속성이 정의된다. )
Key로 정의된 항목이 무조건 존재해야 하며, 이를 통해 Entity Type간에 association을 정의할 수 있다
Property : EntityType밑에서 각 Column을 정의할 때 사용한다.
NavigationProperty : Entity Type의 외 래키를 설정해 준다. ( query Option : expand 적용시 나타나는 형태임 )
ComplexType : itab에 nested itab을 구성하고 그 밑에 nested itab을 구성하고자 할때 사용하는 structured type이다.

ComplexType을 이용하여 nested itab을 구성할 수 있다
EntitySet(Collection) : 어떠한 EntityType을 사용하여 외부에 보여져야 하는 EntitySet의 이름은 무엇이다라고 정의한다.
일반적으로 EntityType과 EntitySet의 유사하게 정의한다.
Association : 외래키 설정을 위한 선언정보가 들어간다.
entityType간의 관계를 설정한다. cardinality rule과 association에 사용될 구성원을 지정한다.
<?xml version="1.0" encoding="utf-8" standalone="yes"?>

<!-- EntitySet[Table]을 정의해 준다.-->
<!-- Namespace = "NavigationModel" 이 부분이 기본값이 된다.-->
<!-- EntityName = "Employee"로 정의되면 Entity Type = "NavigationModel.Employee"-->
<Schema Namespace="NavigationModel"
xmlns:d ="http://schemas.microsoft.com/ado/2007/08/dataservices"
xmlns:m ="http://schemas.microsoft.com/ado/2007/08/dataservices/metadata"
xmlns ="http://schemas.microsoft.com/ado/2008/09/edm">
<!-- Entity(Table)을 정의한다. -->
<EntityType Name="Employee">
<Key>
<PropertyRef Name="EmployeeID"/> <!-- Primary Key를 지정한다. Property로 EmployeeID가 존재해야 한다 -->
</Key>
<Property Name="EmployeeID" Type="Edm.Int32" Nullable="false"
p8:StoreGeneratedPattern="Identity" xmlns:p8="http://schemas.microsoft.com/ado/2009/02/edm/annotation"/>
<Property Name="Name" Type="Edm.String" Nullable="false" MaxLength="20" Unicode="true" FixedLength="false"/>
<Property Name="ResumeID" Type="Edm.Int32" Nullable="true"/>
<!-- ERD의 Relation을 정의한다. -->
<!-- Employee의 키값을 확인된 Row는 EntityType Name[Resume]로 연관되어 있다.-->
<!-- 해당 관계에 대한 정보는 [NavigationModel.FK_Employees_Resumes]를 확인하면 된다. -->
<NavigationProperty Name="Resume" Relationship="NavigationModel.FK_Employees_Resumes" FromRole="Employees" ToRole="Resumes"/>
</EntityType>
<!-- Entity(Table)을 정의한다. -->
<EntityType Name="Resume">
<Key>
<PropertyRef Name="ResumeID"/>
</Key>
<Property Name="ResumeID" Type="Edm.Int32" Nullable="false"
p8:StoreGeneratedPattern="Identity" xmlns:p8="http://schemas.microsoft.com/ado/2009/02/edm/annotation"/>
<Property Name="Hobbies" Type="Edm.String" Nullable="true" Unicode="true"/>
</EntityType>

<!--
ERD의 Relation을 정의한다.
Employee->Resume는 1:1의 관계이며 Resume는 없을수도 있다.(Cardinality)
이 Cardinality에 해당하는 Field는 Employee[ResumeID]-Resume[ResumeID]를 사용한다.
-->
<Association Name="NavigationModel.FK_Employees_Resumes">
<End Role="Employees" Type="NavigationModel.Employee" Multiplicity="1"/>
<End Role="Resumes" Type="NavigationModel.Resume" Multiplicity="0..1"/>
<ReferentialConstraint>
<Dependent Role="Resumes">
<PropertyRef Name="ResumeID"/>
</Dependent>
<Principal Role="Employees">
<PropertyRef Name="ResumeID"/>
</Principal>
</ReferentialConstraint>
</Association>

<!--
외부에서 보여질 정보를 정의한다.
Entity[Employee]는 외부에서(EntitySet) Employees로 보여질 것이다.
Entity[resume]는 외부에서(EntitySet) Resumes로 보여질 것이다.
Function(FindEmp)를 외부에서 호출할 수 있다.
Relation은
Employees->Resumes로 정의된다.
-->
<EntityContainer Name="NavigationEntities" p7:LazyLoadingEnabled="true" m:IsDefaultEntityContainer="true"
xmlns:p7="http://schemas.microsoft.com/ado/2009/02/edm/annotation">
<EntitySet Name="Employees" EntityType="NavigationModel.Employee"/>
<EntitySet Name="Resumes" EntityType="NavigationModel.Resume"/>
<FunctionImport Name="FindEmp" EntitySet="Employees" ReturnType="Collection(NavigationModel.Employee)" m:HttpMethod="Get" />
<AssociationSet Name="FK_Employees_Resumes" Association="NavigationModel.FK_Employees_Resumes">
<End EntitySet="Employees" Role="Employees"/>
<End EntitySet="Resumes" Role="Resumes"/>
</AssociationSet>
</EntityContainer>
</Schema>
</edmx:DataServices>
</edmx:Edmx>
3) 테이블의 데이타(EntitySet)를 읽어본다.
=> https://services.odata.org/TripPinRESTierService/(S(id))/Airports


JSON View를 설치하면 이렇게 보인다.
3-1) EntitySet중 특정Entity만 읽어들이려면 키값을 알아야 한다.
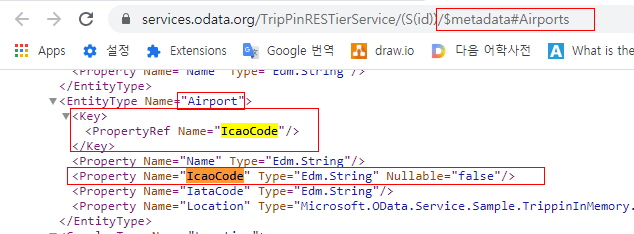
metadata를 통해 airport(entityset)의 Key가 IcaoCode 1개인 것을 확인하였다.

Key가 1개이므로 바로 값을 입력하여 조회할 수 있다. 만약 키가 2개라면.?

키값을 명시적으로 넘겨주어 조회하면 된다.

개발자도구에서 보면, Airpots라는 파일을 Respond받는데 , Request로 어떤 URL을 받고 Method는 Get이고 Status : 200(OK)임을 확인할수있다
만약 Key값이 1개가 아니고 2개 이상이라면 아래의 방식으로 접근하고 중간에 콤마[ , ]가 삽입된다. 콤마좌우에 공백이 없어야 한다.
Airport(IcaoCode='KSFO',country='KOREA')
4) 전체 데이타가 리턴된 것이 확인되었으므로, 내가 원하는 데이타만 읽어보자. (Querying Data : select )
=> oData의 select [Query]를 사용할 것이다.
=> URL에서 [?]이하를 [query]라고 부른다.
=> select라는 query를 사용하고 return되기를 원하는 필드를 넣어준다.
=> https://services.odata.org/TripPinRESTierService/(S(id))/Airports?$select=Name,IcaoCode

5) [ Querying Data ]의 옵션 skip , top에 대해 알아본다.
=> skip은 특정 row_id 의 값을 생략해 준다.
=> 상위 몇개의 row를 리턴해 줄지 제한해 준다.
=> 만약 화면에 10개씩의 데이만 보여주는 화면이라면 2번째 PAGE를 가져오는 경우 $skip=10&top=10 을 주면 된다.
=> 아래의 이미지를 보면 query가 추가해야 되므로 [&]표시로 추가된 query가 있음을 알려준다.
(아래의 두 이미지를 보면 skip에 의해서 밀려서 나타나는 것을 확인할 수 있다)


6) [ Querying Data ]의 옵션 count에 대해 알아본다.
=> Returning Data에 Return되는 Rows의 count정보를 보여준다.
=> count=true가 적용된것과 안된것을 비교해 보도록 하자.


7) [ Querying Data ]의 옵션 filter에 대해 알아본다.
=> filter를 어떻게 적용하는지 보여준다.
=> filter는 가장 중요한 항목중에 하나이다. ABAP의 Selection-Screen의 검색조건을 이 항목을 통해 Server로 전달하게 된다.
=> https://services.odata.org/TripPinRESTierService/(S(id))/Airports?$filter=contains(Name,'San')

8) [ Querying Data ]의 옵션 정렬 orderby에 대해 알아본다.
=> orderby도 많이 사용하는 option이다.
=> https://services.odata.org/TripPinRESTierService/(S(id))/Airports?$orderby=Name
